Designing a Resilient Infrastructure
|
Cette page est à ce jour disponible en anglais uniquement. |
Today having a website or a service down can have a massive impact on your brand image or your business. In traditional IT, a resilient architecture was difficult to design or was very expensive because the infrastructure was not modular.
This topic provides quick and easy steps toward a resilient infrastructure.
General Information
High Availability
Downtime
In a year, how long can you afford to have your service down? Today the "five nines" is the target for major web players. To reach that target, a flexible and resilient infrastructure is mandatory.
| Rate | Time per year |
|---|---|
99% |
3.65 days |
99.9% |
8.76 hours |
99.99% |
52.56 minutes |
99.999% (five nines) |
5.26 minutes |
99.9999% |
31.5 seconds |
Performances
We consider that a website must have a response time of 5 seconds maximum, and aim for an average response time of 2 to 3 seconds. Load balancing provides an easy way to achieve this, without compromising performance regardless of website sessions.
However, multiplying layers and services can slow down the overall user experience. For that reason, you should consider designing your solution with asynchronous communication mechanisms that rely on communication bus with AMQP (see RabbitMQ or Apache Kafka).
Redundancy
In order to guarantee your customers maximum availability whatever happens in a physical datacenter, you can benefit from our Regions and Subregions. For more information, see À propos des Régions et Sous-régions.
What to Leverage
Infrastructure Architecture
Going to the Cloud enables you to use mechanisms such as Régions et Sous-régions and Load Balancers to design a High Availability and a Load Distribution infrastructure without modifying your application stack.
Software Architecture
After designing your infrastructure, you can improve or design a new application according to rules that enable you to reach the state of the art of a clustered application. You can also design your software to be fault tolerant. For more information, see Netflix Chaos Monkey.
Infrastructure Architecture
Philosophy
The main thing to do is to install each service or application on a single virtual machine (VM) and create an OUTSCALE machine image (OMI) from it. This enables you to easily replicate a VM and deploy it several times. For more information, see Créer une OMI.
A single service needs to be provided by many VMs (see SPOF). A VM with a service is called a "node", and the collection of "nodes" providing a service is called a "cluster". For more information, see Computer Cluster Wikipedia.
Each cluster contains a load balancer that receives incoming traffic. Your VMs should never receive direct incoming traffic.
Best Practices
-
Run each of your critical services or jobs on a single VM, such as 3-tier pattern.
-
Make your infrastructure grow in scale out mode, not up scale mode, that is, you need to add nodes when overloading instead of resizing a single node.
-
Use several Subregions to guarantee your service.
Subnets and Security Group Isolation
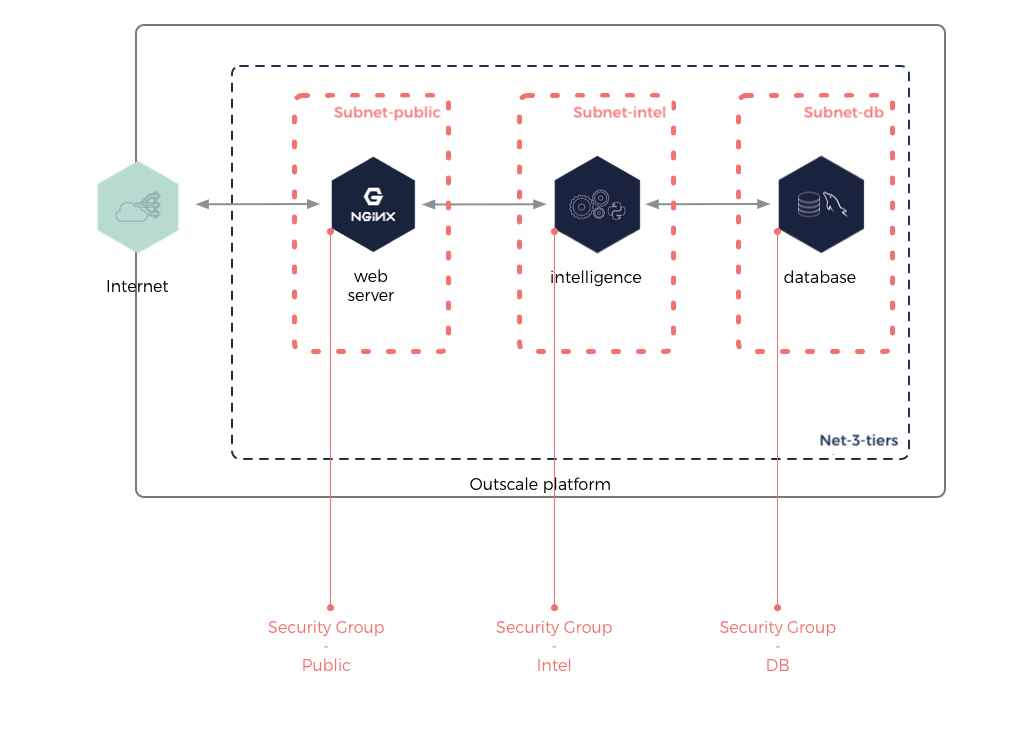
Because Cloud Computing provides a philosophy of security by design, we use Nets and Subnets to logically isolate each business layer and your overall infrastructure to other infrastructures. For more information, see Créer et gérer des Subnets dans un Net.
Three VMs are created from existing OUTSCALE machine images (OMIs). Each VM has its own dedicated security groups, and is placed in a Subnet dedicated to a single business logic.
The mechanism is consistent: for 1 business logic, you get 1 OMI, 1 Subnet and 1 security group. Elements discussed here appear in red in the graph below:
Out Scaling
Instead of having one VM per service which is growing (more CPU, more RAM) that is called up scaling, we prefer to distribute the load across several machines. To do that, the load of each business layer is distributed through a load balancer. For more information, see Load Balancing Unit (LBU).
Databases can not be managed with Load Balancers.
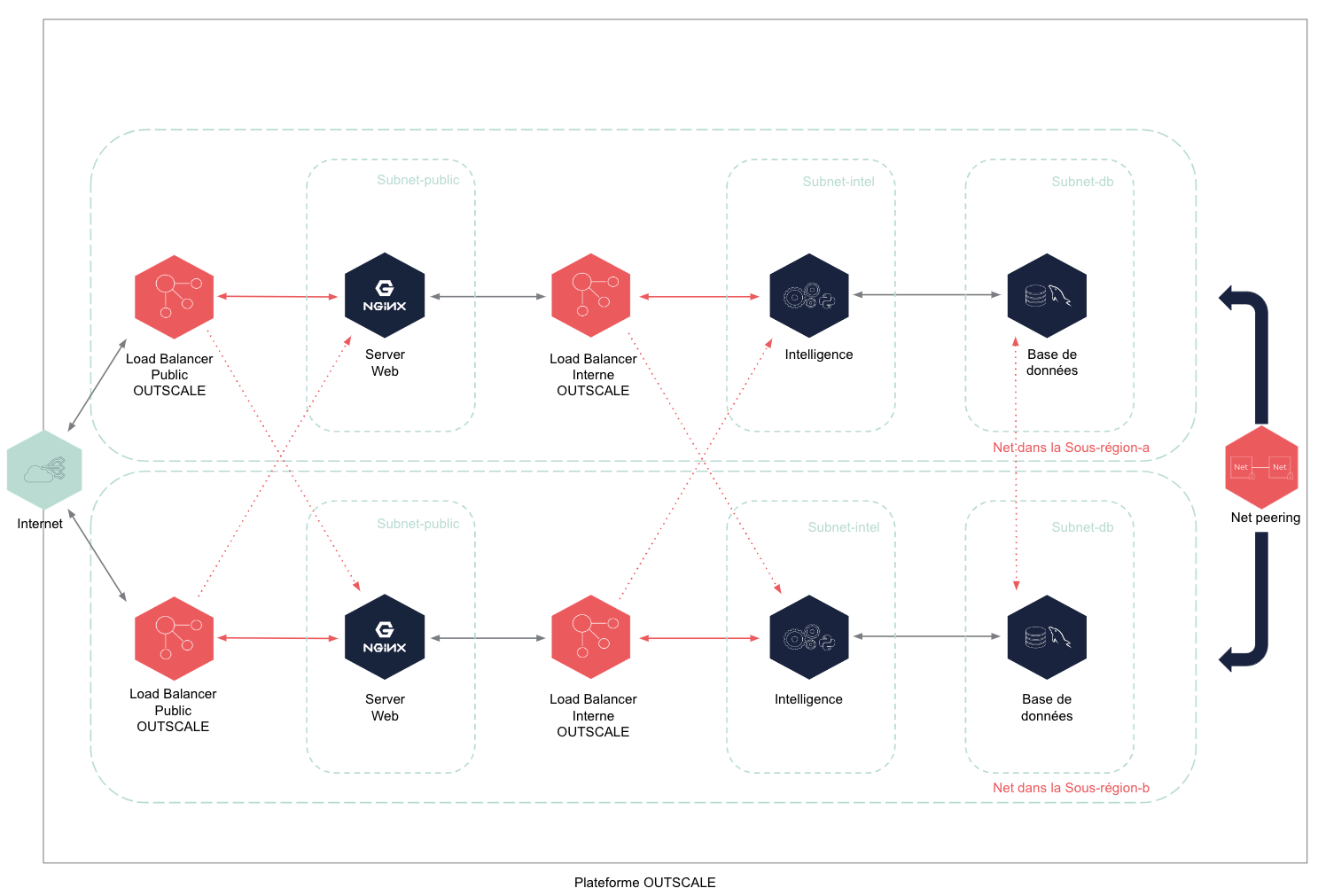
Creating a Multi-Subregion Architecture
Based on existing OMIs, you can run multiple business nodes by replicating the previous infrastructure and crossing flows between load balancers and nodes. These elements appear in red in the graph below.
To create a resilient architecture ensuring redundancy and high-availability, we advise separating each horizontal layer (web server, intel, or database) in distinctive Subnets and in different Subregions.
|
The available Subregions per Region are listed in À propos des Régions et Sous-régions. |
-
Create a first Net. For more information, see Créer un Net.
-
Create a subnet in this Net in the Subregion A.
For more information, see Créer un Subnet dans un Net.In this example, we choose the Subregion A. You can choose any Subregion you want provided that the second Net is in a different Subregion.
-
Create a second Net. For more information, see Créer un Net.
-
Create a subnet in this second Net in the Subregion B.
For more information, see Créer un Subnet dans un Net.In this example, we choose the Subregion B. You can choose any Subregion as long as it is different from the Subregion you chose for the first Net.
-
Create a Net peering between these 2 Nets. For more information, see Créer un Net peering.